The Problem Nobody Talks About
Imagine this: Your phone’s keyboard learns to predict the next word you’re about to type. That’s incredibly useful. But how does it work?
Traditionally, here’s what happens:
- You type on your phone
- Every keystroke gets sent to a company’s server
- The server trains a model on millions of people’s typing data
- The improved model comes back to your phone
Sounds fine, right? Except… all your personal typing habits, your text shortcuts, the way you write to your friends—it’s all sitting on someone else’s server. Your medical searches, your work messages, your embarrassing typos. Everything.
This is where federated learning comes in. And honestly, it’s pretty elegant.
What is Federated Learning?
Let’s break it down with a simple analogy:
Traditional Learning (Centralized):
- Everyone sends their personal notebook to the central library
- The library reads all the notebooks and learns from them
- The library sends back a summary
Federated Learning (Distributed):
- Everyone keeps their notebook at home
- Each person reads their notebook and learns from it locally
- Everyone shares only what they learned (not the notebook itself)
- All the local learnings are combined into one master understanding
That’s it. In federated learning, your data never leaves your device. Only the “lessons learned” get shared.
Explanation (Real-World Example)
Google’s Gboard keyboard works exactly like this. When you type, your phone learns locally. Your typing patterns stay on your phone. Only the tiny model updates—essentially just numbers representing what the model learned—get sent to Google’s servers. Millions of phones do this, the server combines all the tiny updates, and boom—everyone’s keyboard gets smarter without anyone sharing their actual messages.
Why Do We Need This? (The Real Problems)
1. Privacy is a Massive Deal
Think about what would happen if your health data was centralized:
- Insurance companies could see your browsing history
- Employers could know you searched for anxiety treatments
- Advertisers could target you based on your health concerns
With federated learning, your health data never leaves your device. Your doctor’s office trains on it locally, and only sends the model updates. Your privacy stays intact.
2. Trust Issues
Remember all those data breaches in the news? Yahoo, Target, Equifax… When companies centralize data, hackers have a big fat target. With federated learning, there’s nothing to steal because the data never travels.
3. It’s Just More Efficient
Sending gigabytes of data from every user to a server uses massive bandwidth. Sending tiny model updates? Much more efficient. Your phone doesn’t have to upload your entire browsing history—just what the model learned.
4. Connection Problems
What if you’re on a train with spotty WiFi? A centralized system needs constant connection. Federated learning lets your phone keep learning offline, then sync when you’re back online.
Note (Why Companies Actually Care)
It’s not just privacy evangelists who want this. Companies save money on bandwidth, storage, and compliance costs. They avoid massive liability if they get hacked. Win-win.
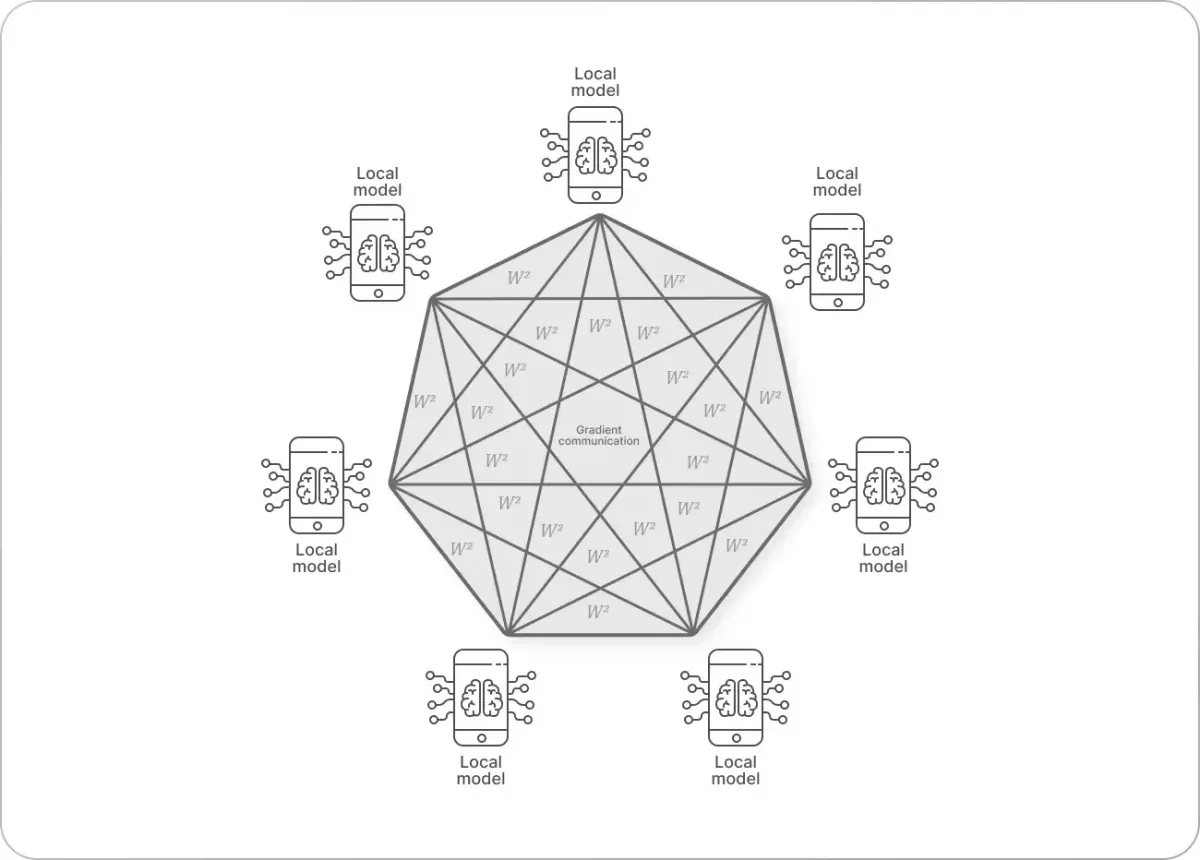
How Does Federated Learning Actually Work?
Okay, let me walk you through the process:
Round 1: The Setup
Central Server: "Hey everyone, here's the current best model"The server has a smart model (let’s say it predicts the next word). It sends this model to everyone’s phones.
Round 2: Local Learning
Your Phone: "Okay, let me practice with MY data"My Phone: "I'm learning too, with my own messages"Another Phone: "Me three!"Each person’s phone trains the model using only that person’s data. This happens offline. Nobody sees anyone else’s data.
After training, each phone has a slightly improved version of the model. Maybe your version learned that you often type “haha” after “that’s funny,” while my version learned something different.
Round 3: The Update
All Phones: "Here's what we learned!"(They send back the improved model, not the data)The phones send back their slightly-improved models. Not the data. Not what was typed. Just the model.
Round 4: The Combination
Central Server: "Let me combine all these learnings..."The server takes all the improved models from all the phones and combines them into one super-improved model. This is where the magic happens. The server uses something called FedAvg (Federated Averaging) to blend them all together fairly.
Round 5: Repeat
Central Server: "Here's the new, improved model!"(Goes back to Round 1)The updated model goes back to all the phones. Everyone now has a smarter model, and nobody’s personal data left their device.
Tip (The Beautiful Part)
The server never sees your raw data. It only sees the models that learned from your data. It’s like getting advice from a friend about a secret—they don’t tell you the secret, just what they learned from it.
The Real-World Problems it Solves
Problem #1: Data Silos
What’s a silo? When data is locked in different places—your hospital has your health data, your bank has your financial data, your phone company has your location data—none of them can work together. This is called being “siloed.”
The old solution: Combine all the data in one place. Terrible for privacy.
Federated learning solution: Keep data where it is. Train models locally. Share only the improvements. Everyone gets smarter models without consolidating dangerous databases.
Problem #2: Privacy Regulations (GDPR, etc.)
The EU’s GDPR basically says: “You can’t just collect and store everyone’s personal data.” Breaking it costs billions in fines.
The old solution: Anonymize the data (doesn’t really work, by the way).
Federated learning solution: Never collect it in the first place. Train models right where the data lives. Boom—no GDPR violations.
Problem #3: Sensitive Industries
Imagine training a cancer detection model. Hospitals want to collaborate, but they can’t share patient data—that’s HIPAA (health privacy law).
The old way: Hospitals refuse to share, so the model stays mediocre.
Federated learning way: Each hospital trains on its own data locally. All hospitals’ learnings combine into a super-accurate model. Nobody’s patients were exposed.
Problem #4: Speed and Bandwidth
Autonomous cars generate terabytes of video data. Sending all of it to a server is slow and expensive.
The old way: Upload everything, wait for the model to improve, download the new model.
Federated learning way: Process locally, send only the model updates (kilobytes instead of terabytes). Training gets faster, bandwidth stays reasonable.
Example (Real Example: Autonomous Vehicles)
Tesla’s cars can’t send all their dashcam footage to servers (way too much data). Instead, each car learns locally from what it sees. When it encounters something unusual, the learning gets shared with all other cars. Everyone benefits without sharing raw video footage.
What About System Heterogeneity? (Fancy term, simple concept)
Here’s a real problem: Not all devices are equal. Your brand new laptop is way faster than a budget phone from 2019. That phone might be running on a metered connection while the laptop has WiFi.
In federated learning: Each device trains at its own pace. A slow phone trains with smaller batches, a fast laptop trains with bigger batches. Everyone finishes eventually. The server doesn’t wait for stragglers. Everyone’s contributions are still valued fairly.
It’s like a group project where some people work faster than others, but everyone’s work still counts equally.
When is Federated Learning NOT the Answer?
Be honest—federated learning isn’t a magic solution for everything:
- When you need instant insights: Traditional ML can look at all data immediately. Federated learning takes multiple rounds.
- When devices aren’t reliable: If 90% of phones turn off before finishing training, the model suffers.
- For simple stuff: If you just need to count how many people bought something, federated learning is overkill.
- When accuracy matters most: Federated learning sometimes trades a tiny bit of accuracy for privacy.
Warning (It's a Tradeoff)
Federated learning gives you privacy, but takes slightly longer and is more complex. Traditional centralized learning gives you speed and simplicity, but sacrifices privacy. Choose based on what matters more to your use case.
Real Companies Using This Right Now
- Google: Gboard keyboard, next-word prediction
- Apple: Siri improvements, on-device learning
- Meta: Federated learning on your phone for recommendations
- Tesla: Fleet learning from autonomous vehicles
- Medical institutions: Training cancer detection models without sharing patient data
Wrapping Up
Federated learning is basically: “Keep your stuff private, but help the model get smarter anyway.” It’s a win for privacy-conscious people, a win for companies avoiding liability, and a win for people who just want to use their devices offline without feeling watched.
The coolest part? It’s already happening on your phone right now, silently improving your experience while keeping your data yours.
Pretty neat, right?
Want to Dig Deeper?
Note (Resources for Learning More)
- Papers to Read: The original federated learning paper by Google researchers is called “Communication-Efficient Learning of Deep Networks from Decentralized Data”
- See it in Action: Try building a mini federated learning system yourself (spoiler: it’s simpler than you’d think)
- Regulations: Look up GDPR, HIPAA, and other privacy laws—they’re basically what’s pushing federated learning adoption