Part 1: What Is Redis?
The Desk Analogy
Imagine you’re a librarian in a huge library.
Your filing system is perfect, but documents are stored in the archive—it takes 5 minutes to retrieve anything. To speed things up, you keep frequently requested documents on your desk. Someone asks for “User Profile Document #42”? Boom. Instant access from your desk.
That’s Redis.
Redis stands for Remote Dictionary Server. It’s an in-memory data structure store that keeps your most frequently accessed data in RAM instead of on disk.
Regular Database: Request → Query disk → Parse results → Return (milliseconds)Redis: Request → Check RAM → Return (microseconds)The difference isn’t just faster. It’s orders of magnitude faster.
The Three Truths About Redis
- In-Memory: Data lives in RAM, not on disk
- Single-Threaded: All commands execute sequentially on one thread
- Fast: Every operation is atomic and blazingly quick
But here’s where beginners get confused: Redis isn’t just a cache. It’s more like a specialized database designed for specific use cases. Yes, you can use it to cache data. But you can also use it as:
- A session store (remember user login info)
- A real-time leaderboard (gaming, sports)
- A message broker (app communication)
- A rate limiter (API throttling)
- A real-time analytics engine
- A pub/sub system (real-time notifications)
All because of its speed and rich data structures.
Note
The Big Misconception: “Redis is just a cache I can delete and rebuild anytime.”
Reality: Redis can be your primary database for real-time data. You just need to understand its trade-offs (data in RAM = limited by memory, not persistent by default).
Part 2: Why Is Redis So Incredibly Fast?
You can’t understand Redis without understanding why it’s fast. There are three pillars.
Pillar 1: In-Memory Storage (The Biggest Win)
This is the main reason Redis is so fast.
Memory Access: ~1-100 nanoseconds (billionths of a second)
SSD Access: ~100 microseconds (millionths of a second)
HDD Access: ~5-20 milliseconds (thousandths of a second)
Accessing data from RAM is 1,000-10,000x faster than from disk.
Time for 1 million operations:From disk: 1,000,000 × 10 μs = 10 secondsFrom RAM: 1,000,000 × 0.1 μs = 0.1 secondsThat’s the speed difference. By keeping everything in RAM, Redis eliminates the biggest bottleneck in traditional databases: disk I/O.
When you request data from PostgreSQL or MySQL:
- Check buffer pool (in-memory cache)
- If not there, go to disk
- Read from disk (slow)
- Load into buffer pool
- Return data
Redis skips steps 2-4 entirely. The data is already in memory.
Pillar 2: Single-Threaded Command Execution
This sounds like a limitation. “How can a single thread be fast with thousands of clients?”
The answer is clever: Redis is single-threaded, but clients are handled concurrently.
Here’s why single-threading is actually an advantage:
- No locks needed – If only one thread executes commands, there are no race conditions. No locks. No contention.
- No context switching – The CPU doesn’t waste cycles switching between threads
- No cache invalidation – Each thread has its own cache; single thread uses one cache
- Predictable behavior – Commands execute in order; no unpredictable timing issues
Compare this to multi-threaded databases where you need to acquire locks before reading/writing—all that overhead goes away.
Single-threaded (Redis):[Command 1] → [Command 2] → [Command 3]No synchronization needed, blazing fast
Multi-threaded (Traditional DB):Thread 1: [Command 1] → (acquire lock) → (do work) → (release lock)Thread 2: [Command 2] → (waiting for lock...) → (acquire) → (do work) → (release)Thread 3: [Command 3] → (waiting for lock...) → (waiting...) → (acquire) → (do work)More overhead, more latencyPillar 3: Highly Optimized C Code and Data Structures
Redis is written in ANSI C—a language known for performance. Beyond that, every data structure is custom-built and optimized.
Examples:
- Simple Dynamic Strings (SDS): Instead of standard C strings, Redis uses a struct that stores length metadata. This makes getting the string length O(1) instead of O(n).
- Ziplists: For small hashes and sets, Redis stores data in a compact, contiguous block of memory. No pointers, no fragmentation, just raw efficiency.
- Intsets: Integer sets are stored as sorted arrays without any overhead.
The result? Less memory, less CPU usage, faster operations.
Note
Why this matters: Understanding that Redis is fast because of RAM access, not because of magic, helps you understand its limitations. If you have more data than RAM, Redis struggles. If you need persistent storage, you need additional mechanisms. Speed is a trade-off.
Part 3: The Architecture: How Redis Handles Thousands of Clients
Here’s the question every engineer asks: “You said Redis is single-threaded. How does it handle thousands of concurrent client connections?”
The Kitchen Analogy
Imagine you’re a chef. You can only cook one dish at a time (single-threaded). But you have sous chefs (the operating system) watching multiple burners.
You (Redis main thread): Chopping veggiesSous Chef 1 (OS): "Chef, burner #3 is ready!"You: Drop your knife, plate burner #3You: Go back to chopping veggiesSous Chef 2 (OS): "Chef, burner #1 is ready!"You: Plate burner #1, go back to choppingIn reality, here’s what happens:
- Client connects → OS registers their socket
- Client sends command → OS notifies Redis via
epoll(Linux) orkqueue(macOS) - Redis reads command → Executes it on the main thread
- Redis sends response → OS handles the actual network transmission
- Redis goes back to listening → Waits for the next event
This is called event-driven I/O multiplexing. The operating system efficiently watches thousands of sockets and notifies Redis which ones are ready. Redis doesn’t sit around waiting—it’s always doing something.
The Process Flow
┌──────────────────────────────────────────────────────┐│ Redis Event Loop (Single Thread) │└──────────────────────────────────────────────────────┘ │ ┌───────────────┼───────────────┐ │ │ │ ▼ ▼ ▼┌──────────────┐ ┌──────────────┐ ┌──────────────┐│ Client 1 │ │ Client 2 │ │ Client 3 ││ Socket │ │ Socket │ │ Socket │└──────────────┘ └──────────────┘ └──────────────┘ │ │ │ └───────────────┼───────────────┘ │ ▼ ┌──────────────────────────────┐ │ OS (epoll/kqueue/IOCP) │ │ "These sockets are ready" │ └──────────────────────────────┘Result: One thread efficiently handles thousands of connections by never waiting. The OS handles the I/O; Redis just executes commands.
Part 4: Data Structures (Why Redis Is More Than a Cache)
Redis has rich data types. This is what makes it versatile.
String
The simplest type. A key-value pair where the value is text or binary data.
SET username "alice"GET username # Returns "alice"Use case: Storing user preferences, simple caching, counters.
Hash
A mapping of fields to values. Perfect for complex data.
HSET user:1 name "Alice" age 25 city "NYC"HGET user:1 name # Returns "Alice"Use case: Storing user profiles, product details, any object with multiple properties.
List
An ordered sequence. Perfect for queues and timelines.
LPUSH notifications "New comment on post"LPUSH notifications "Friend request from Bob"LRANGE notifications 0 -1 # Get all notificationsUse case: Message queues, chat history, activity feeds, job queues.
Set
An unordered collection of unique values.
SADD tags:post123 "javascript" "redis" "database"SMEMBERS tags:post123 # Get all tagsSISMEMBER tags:post123 "redis" # Is "redis" a tag? (true)Use case: Storing tags, followers, unique visitors, memberships.
Sorted Set
A set where each element has a score. Automatically sorted by score.
ZADD leaderboard 100 "alice" 85 "bob" 95 "charlie"ZREVRANGE leaderboard 0 2 # Top 3 players# Returns: ["alice", "charlie", "bob"]Use case: Leaderboards, real-time rankings, rate limiting by time.
Note
Why data types matter: Each data type has specific commands optimized for its use case. Using the right data type makes your code faster and simpler. A sorted set for leaderboards is 100x better than storing scores in hashes.
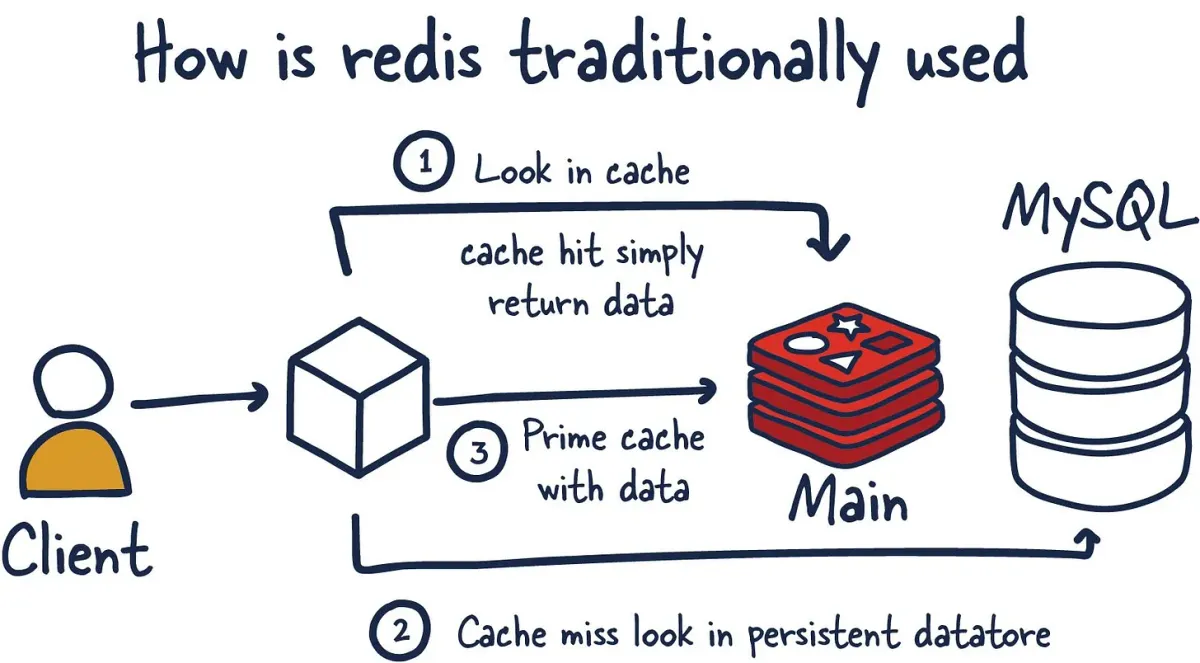
Part 5: Redis as a Cache (The Most Common Use Case)
Let’s say you’re building a user profile page.
Without Redis:
User requests profile↓Query PostgreSQL ("SELECT * FROM users WHERE id = 123")↓Database searches through millions of rows↓Returns data↓Render profile (200-500ms)Every request hits the database. If 1000 users view the same profile, the database executes the same query 1000 times.
With Redis:
User requests profile↓Check Redis: "Does user:123 exist?"↓YES: Return immediately (1-5ms) ← Cache HITORNO: Query PostgreSQL, cache result in Redis, return (200-500ms) ← Cache MISS↓Next user requests same profile↓Check Redis: "Does user:123 exist?"↓YES: Return immediately (1-5ms)The second request is 100x faster.
How to Implement Caching
// Pseudo-code (works in any language)function getUserProfile(userId) { // Check cache cached = redis.get(`user:${userId}`); if (cached) { return cached; // Cache hit }
// Cache miss: go to database user = database.query(`SELECT * FROM users WHERE id = ?`, userId);
// Store in cache with 15-minute expiration (TTL) redis.setex(`user:${userId}`, 900, user);
return user;}Cache Invalidation
The famous saying goes: “There are only two hard things in Computer Science: cache invalidation and naming things.”
When data changes, you must invalidate the cache:
function updateUserProfile(userId, newData) { // Update database database.update(userId, newData);
// Invalidate cache redis.delete(`user:${userId}`);}The next request will cache miss, fetch fresh data, and cache it again.
Part 6: Redis as a Database (Real-Time Leaderboards)
Not every use case needs a traditional database. Real-time leaderboards are perfect for Redis.
The Leaderboard Problem
Imagine a gaming application with millions of players. You need to:
- Update scores instantly as players play
- Show top 10 players instantly
- Allow players to see their rank instantly
A traditional database would be too slow.
The Redis Solution
// Player scores a pointZADD leaderboard 100 "player:123"
// Another playerZADD leaderboard 150 "player:456"
// Get top 10 players (ordered by score, descending)ZREVRANGE leaderboard 0 9 WITHSCORES# Returns: ["player:456", "150", "player:123", "100", ...]
// Get a specific player's rankZREVRANK leaderboard "player:123"# Returns: 2 (they're 2nd)Performance:
- Writing a score: ~1ms
- Getting top 10: ~1ms
- Getting a rank: ~1ms
With SQL, you’d need to sort millions of rows every query. Redis keeps it sorted automatically.
Why This Works
Sorted sets in Redis are implemented using skip lists, a probabilistic data structure. They maintain order while allowing fast inserts and range queries. It’s like having a pre-sorted leaderboard that updates in real-time.
Part 7: Persistence (What Happens If Redis Crashes?)
Redis stores data in RAM. If the server crashes, all data is gone.
“That’s a problem,” you might think.
Redis solves this with persistence mechanisms. Two options:
Option 1: RDB (Snapshots)
Redis periodically takes a snapshot of the entire dataset and saves it to disk.
Time 0: RDB snapshot savedTime 5m: (Redis running, data in RAM)Time 10m: RDB snapshot savedTime 15m: Crash! Server goes downTime 15m+5s: Server restarts, loads last RDB snapshotPros:
- Fast to save (happens in background)
- Fast to restore (one large binary file)
- Perfect for backups
Cons:
- Up to 10 minutes of data loss (depending on snapshot frequency)
- RDB snapshots can be large
Option 2: AOF (Append-Only File)
Redis logs every write command. If it crashes, replay the log to recover.
Time 0: SET user:1 alice → Written to logTime 1: SET user:2 bob → Written to logTime 2: ZADD leaderboard 100 alice → Written to logTime 3: Crash!Time 3+: Server restarts, replays log "SET user:1 alice" "SET user:2 bob" "ZADD leaderboard 100 alice"Pros:
- Minimal data loss (only last 1 second)
- Human-readable log (you can inspect it)
- More durable
Cons:
- AOF files grow larger over time
- Slightly slower write performance
The Recommendation
Use both:
- AOF for durability (continuous logging)
- RDB for backups (periodic snapshots)
Configure AOF to sync every 1 second (good balance between safety and performance).
appendfsync everysec # Best practiceNote
Critical: If data loss is acceptable (cache, sessions), you don’t need persistence. But if you’re using Redis as a primary database (like leaderboards), enable persistence. Understand the trade-offs.
Part 8: Real-World Use Cases
Use Case 1: Session Storage
Store user login information for fast retrieval.
SET session:abc123def456 '{"userId": 789, "role": "admin"}'EXPIRE session:abc123def456 3600 # Expire in 1 hour
# When user returnsGET session:abc123def456 # Instant retrievalWhy Redis: Sessions are accessed on every request. Disk-based sessions are too slow.
Use Case 2: Rate Limiting
Prevent abuse by limiting requests per user.
INCR requests:user:123 # Increment counterEXPIRE requests:user:123 60 # Reset every minute
# If counter > 100, reject requestWhy Redis: You need atomic operations and precise timing. Redis handles this in microseconds.
Use Case 3: Real-Time Chat
Store messages and deliver them to online users.
LPUSH chat:room:general "User A: Hello"LPUSH chat:room:general "User B: Hi there"LRANGE chat:room:general 0 49 # Get last 50 messages
PUBLISH chat:room:general "User A: Hello" # Broadcast to all subscribersWhy Redis: You need fast message storage and pub/sub for real-time delivery.
Use Case 4: Real-Time Analytics
Track metrics in real-time.
INCR page:views:home # Homepage view countZADD user:activity 1703664120 "alice_login" # When user logs inWhy Redis: You need microsecond-level performance for thousands of concurrent events.
Part 9: The Trade-Offs (What You Need to Know)
Redis is amazing, but it’s not perfect.
Limited by RAM
Your dataset can’t exceed available memory. A 128GB Redis instance stores max 128GB of data. A SQL database can store terabytes on disk.
Solution: Use Redis for hot data (recently accessed). Archive old data to disk.
Single-Threaded
CPU-intensive operations block other clients.
// Bad: Blocking operationEVAL (for loop 1 million times) ...
// Good: Quick operationsZADD leaderboard 100 player:123Solution: Keep operations fast. Move heavy computation elsewhere.
Data Loss Risk
Without persistence, a crash loses all data.
Solution: Enable persistence (RDB or AOF).
Complex Queries
Redis isn’t great for complex filtering.
// Redis struggles with this"Find all users aged 25-30 who logged in today"
// SQL excels at thisSELECT * FROM users WHERE age BETWEEN 25 AND 30 AND last_login > TODAYSolution: Use Redis for simple access patterns. SQL for complex queries.
Scaling
A single Redis instance has limits. Scaling horizontally (multiple instances) requires cluster mode, which adds complexity.
SQL handles replication and sharding more naturally.
Note
The Key Insight: Redis is a specialized tool. It’s not a replacement for SQL databases. It’s a complement. Use Redis for speed-critical operations, and SQL for complex queries and long-term storage.
Conclusion: The Big Picture
Redis is simple: an in-memory data structure store optimized for speed.
It’s single-threaded but handles thousands of concurrent clients through efficient I/O multiplexing. It’s fast because it stores everything in RAM and uses optimized data structures.
But it’s not magic. It trades durability for speed, storage capacity for performance. It’s perfect for specific problems:
- Caching: Replace slow database queries
- Sessions: Store user login info
- Leaderboards: Real-time rankings
- Rate limiting: Prevent abuse
- Real-time features: Chat, notifications, analytics
- Message brokers: Queue jobs, pub/sub messaging
It’s not perfect for everything. Use Redis where speed matters. Use SQL where durability and complex queries matter.
Next Steps
- Practice: Spin up Redis locally and experiment with different data types
- Read: Check out the official Redis documentation
- Deep dive: I will be writing more blogs on redis in the coming days, you can check them out for a deeper understanding of certain concepts
- Production: When you use Redis in a real application, measure its impact with monitoring tools like Redis Insight or Datadog
Redis isn’t just a cache. It’s a powerful, elegant tool. Once you master it, you’ll understand why it’s used by companies like Netflix, Twitter, and GitHub.
Happy caching!